How it works
Two routes produce the latent embeddings the projector reads from:
- VAE + Synth — a self-supervised variational autoencoder trained from scratch to reconstruct the input, with a projector on its bottleneck that decodes the Pink Trombone’s articulatory parameters.
- Pretrained encoders — EnCodec and Wav2Vec supply the latent space directly, so only the projector is trained. This removes the from-scratch encoder, simplifying the pipeline and cutting compute.
Because the synthesizer is a physical model, the predicted parameters are directly interpretable as vocal-tract gestures rather than opaque features.
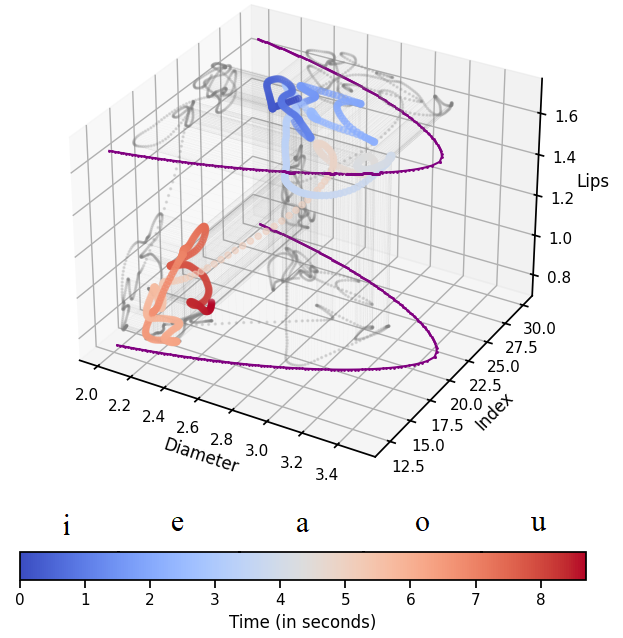
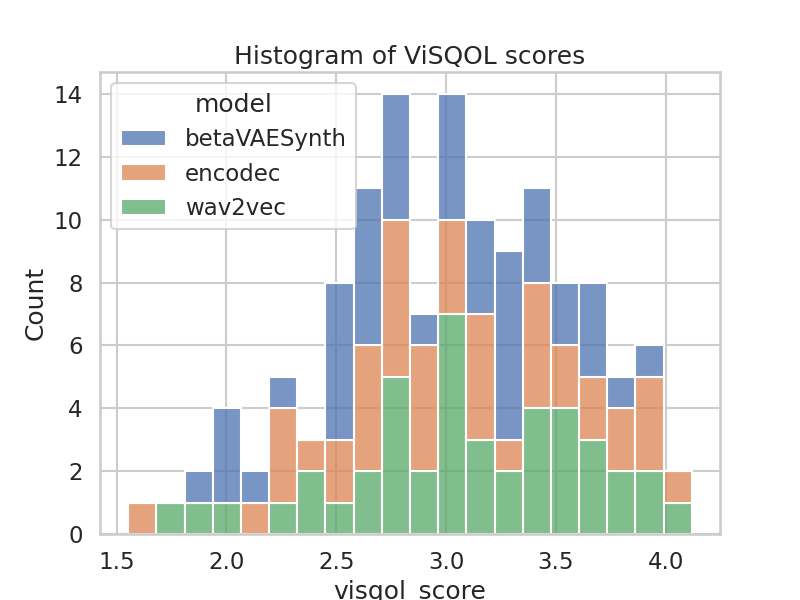
Listen
For every example: the original human recording, then the reconstruction from each encoder’s predicted parameters, in a slow variant (steady parameters) and a fast variant (up to 10 parameter changes across the utterance).
Cite
@article{camara2024decoding,
title = {Decoding Vocal Articulations from Acoustic Latent Representations},
author = {C{\'a}mara, Mateo and Marcos, Fernando and Blanco, Jos{\'e} Luis},
journal = {arXiv preprint arXiv:2406.14379},
year = {2024}
}
Vowel reconstructions
Original human recording vs. articulatory parameters predicted by each encoder, fed back through the Pink Trombone synthesizer. "Slow" holds parameters steady; "fast" allows 10 changes across the utterance.
| Example | Original | VAE+Synth · slow | VAE+Synth · fast | Wav2Vec · slow | Wav2Vec · fast | EnCodec · slow | EnCodec · fast |
|---|---|---|---|---|---|---|---|
| /a/ | |||||||
| /e/ | |||||||
| /i/ | |||||||
| /o/ | |||||||
| /u/ | |||||||
| /e–i–u/ | |||||||
| roy | |||||||
| /i–e–a–o–u/ | |||||||
| /o–i–u/ | |||||||
| /a–i–o/ |