We present an open-source system for multilingual translation and speech regeneration. Whisper handles speech recognition, with Voice Activity Detection to find speaking intervals, followed by a pipeline of large language models: one segments speech into coherent sentences, a second translates them. A text-to-speech module with voice cloning then regenerates the speech in the original speaker's voice, preserving naturalness and identity. Components run locally or via APIs, enabling cost-effective deployment — real-time translation in video calls, regeneration for broadcasts, Bluetooth multilingual playback — while a detailed analysis of latency and word accuracy demonstrates its potential for inclusive, real-world communication.
Pipeline
Audio in → Whisper transcription with voice-activity detection → an LLM that
segments the transcript into complete sentences → a second LLM that translates them
→ a voice-cloning TTS that regenerates speech in the original speaker’s voice. Every
stage can run locally or through an API, so the system scales from a laptop to a server.
Results
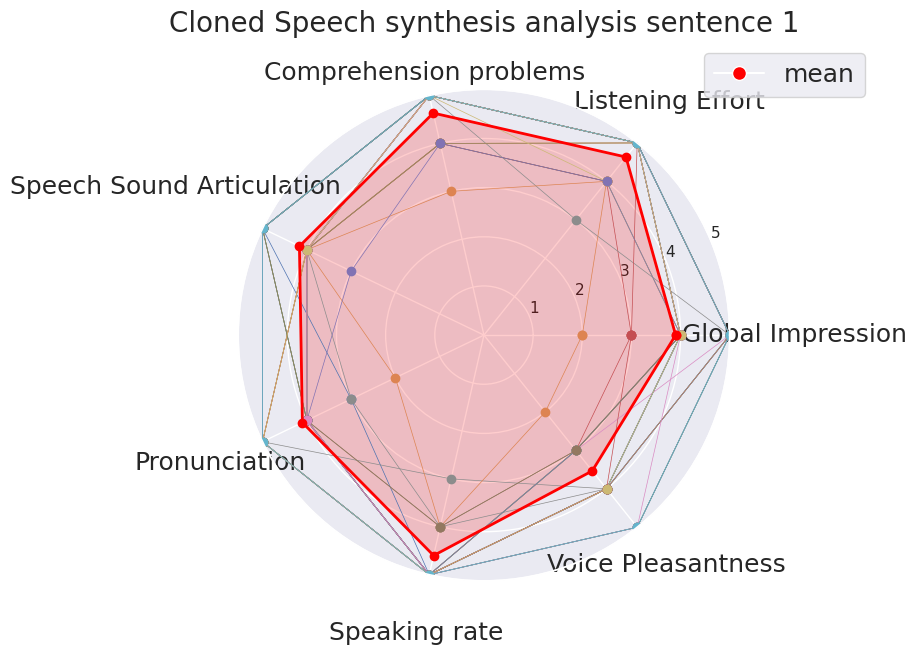
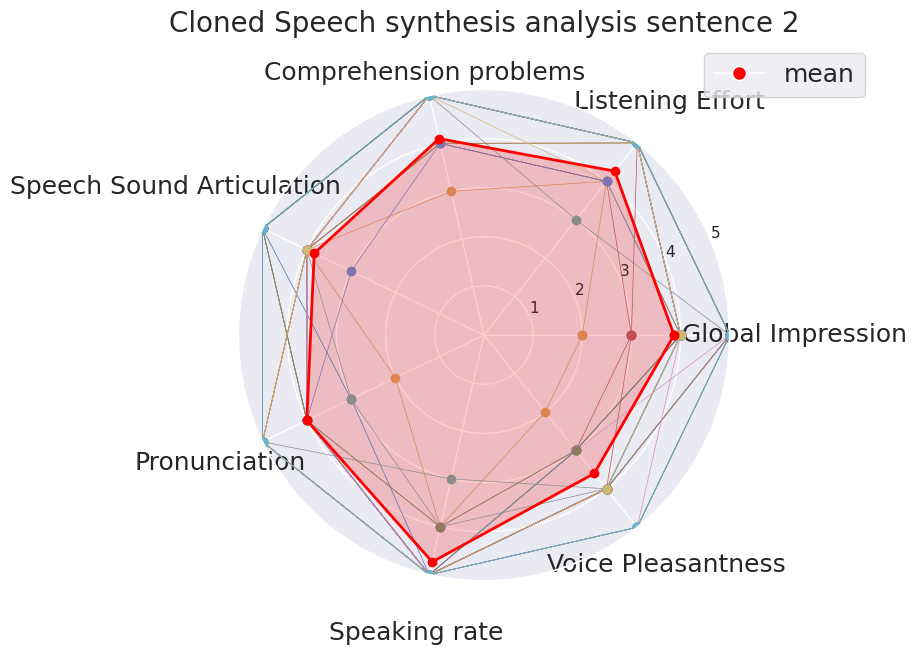
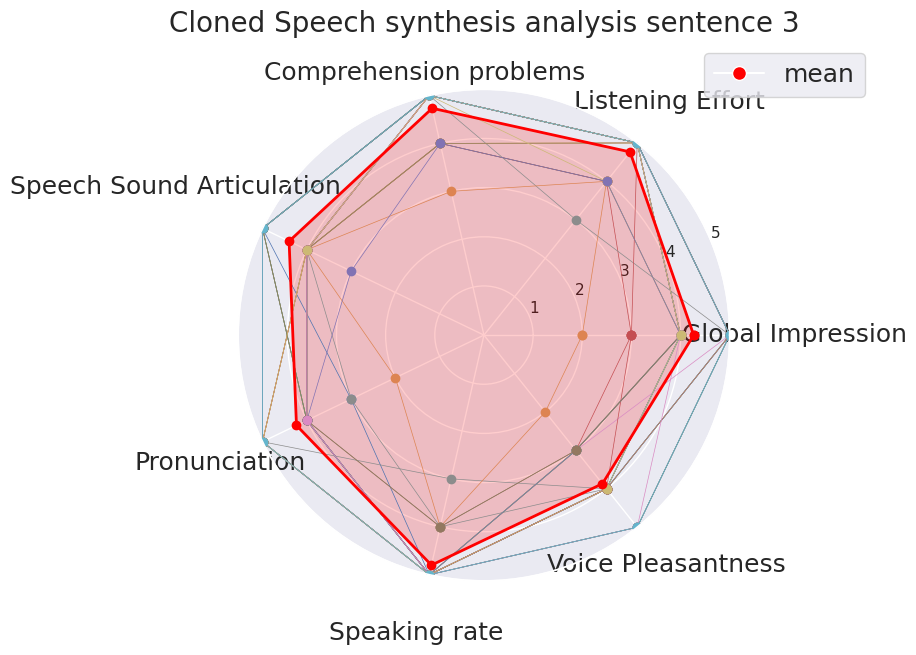
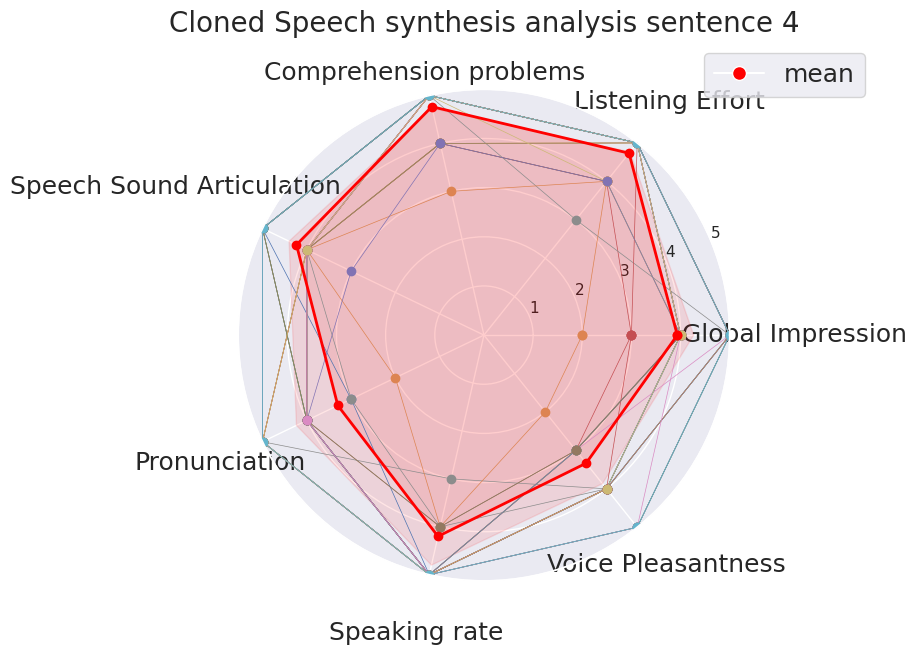
Subjects scored the system sentence by sentence:
Sentence 1Sentence 2Sentence 3Sentence 4
Listen
Standalone outputs presented to listeners:
Sample 1Sample 2
And the paired test-vs-reference comparisons:
Paired samples — test vs. reference
Each translated-and-cloned output beside the human reference shown to listeners in the subjective test.